
Serverless Computing
and Machine Learning
Preface
When I joined Thermo Fisher Scientific in 2011, I had started a conversion rate optimization(CRO) program to get better conversions for digital marketing campaigns and our eCommerce website with over a million web pages comprised of four major platforms. We've learned a lot about customer buying behavior and of course that translated into consistent solid eBusiness revenue growth and organizational knowledge.

Find Early Adopters
I've learned that in an enterprise environment, ideas need to be marketed and sold for further support, which I really enjoyed doing (it reminded me of my tech startup days)! And because of the various experiments that I've conducted over the years, I had a lot of proof but that was not enough. However, if I had a working automated prototype, that would be even better!
Before the creation of a near-serverless prototype, I created a very small prototype on my laptop using real data that constituted of:
- Any data related to identifying the customer
- Clicks
- Visited pages
- SKU’s added to cart
- SKU’s they’ve copied
- Downloaded product manuals (which aids in conversion by the way...)
- Form submits
I used PredictionIO (months before Salesforce acquired it) because it was a free and open source machine learning engine. Then I output the recommendations in JSON format which could be used to create dynamically assembled ads with Javascript. At the time we had a creative department that was manually creating the ads, a time and resource intensive process that slowed our pace of execution.
I demoed the prototype to my team and leadership. About two weeks after the demo, I earned more support.
Knowing My Customers
At the time, product recommendations were rendered manually by former bench scientists that work on the business side and also sales and marketing analysts. They would pick out products based on a variety of methods such as previous purchasing behavior, statistics, and scientific workflows that follow the central dogma of molecular biology. Not one method would prevail but rather a contextual use instead.
With machine learning, it would be possible to combine those methods in the form of highly customized algorithms to bring personalized near real-time automated recommendations to customers and improve their shopping experience.
For automated product recommendations to be possible, the behaviors of the customer must be repeatable and actionable. From my previous research, there are repeatable shopping patterns but not everyone has the same pattern. And not every customer is a B2C customer. In our B2B customer type, we have more than 5 subtypes. And because we do business globally, not all customers transact through the website alone. I had to define a limited scope where I’m not boiling the whole ocean, but rather a very targeted prototype for a specific set of customers.
Here’s the targeting criteria of the prototype:
- North America market only
- B2C
- Customers who are in a logged in state and visit the website more than once per week for almost every month of the year.
- Take into account for seasonal behaviors: universities and life sciences companies purchase less during summer and winter months.
- Prototype is placed at the most visible and highly trafficked web pages where I can create specific targeting criteria to serve up recommendations that were contextually relevant to the information architecture of the website.
How my customers shop:
- Most of the time, scientists put the shopping list together. They browse the website, click on merchandising ads, download manuals, open emails, fill out forms to view webinars and eBooks, etc.
- Some scientists add to cart. Some scientists copy and paste into an email or spreadsheet and forward to their purchaser or principal investigator.
- The purchaser or principal investigator conducts the transactions through procurement systems or use a credit card at the website. There’s also budget considerations so scientists may not get everything they’ve asked for.
- Because there’s a purchaser or principal investigator doing the buying, it’s very difficult to attribute the sale to the end user, the scientist.
- Procurement systems leave a very small data footprint and don’t play well in a digital marketing context.
Building The Product
Recommendations Engine
I decided that the prototype needed to be cloud native so we can develop faster and not worry about migration challenges down the road. Naturally, AWS is the clear solution.
Also, it needed to also be near serverless as possible for three primary reasons:
- Reduced operating costs, we pay for only what we use.
- Allows my team to focus on perfecting product recommendations and less on managing infrastructure.
- Take advantage of the evolving AWS ecosystem of services. Also, utilize AWS enterprise support when needed.
In 2015, serverless machine learning engines did not exist on AWS yet, so I chose PredictionIO because it was:
- Free and open source.
- Had generic algorithms for recommendations we could learn from and modify.
- A very active community of developers with documentation.
- Ease of use and implementation.
PredictionIO was the only part of the engine where I needed to use an EC2 M4.xlarge.
The alternatives at the time were too expensive because they ran on traditional servers and were closed source. This translated to “we had to pay for customizing algorithms and rely on professional services instead”.
Simplified AWS
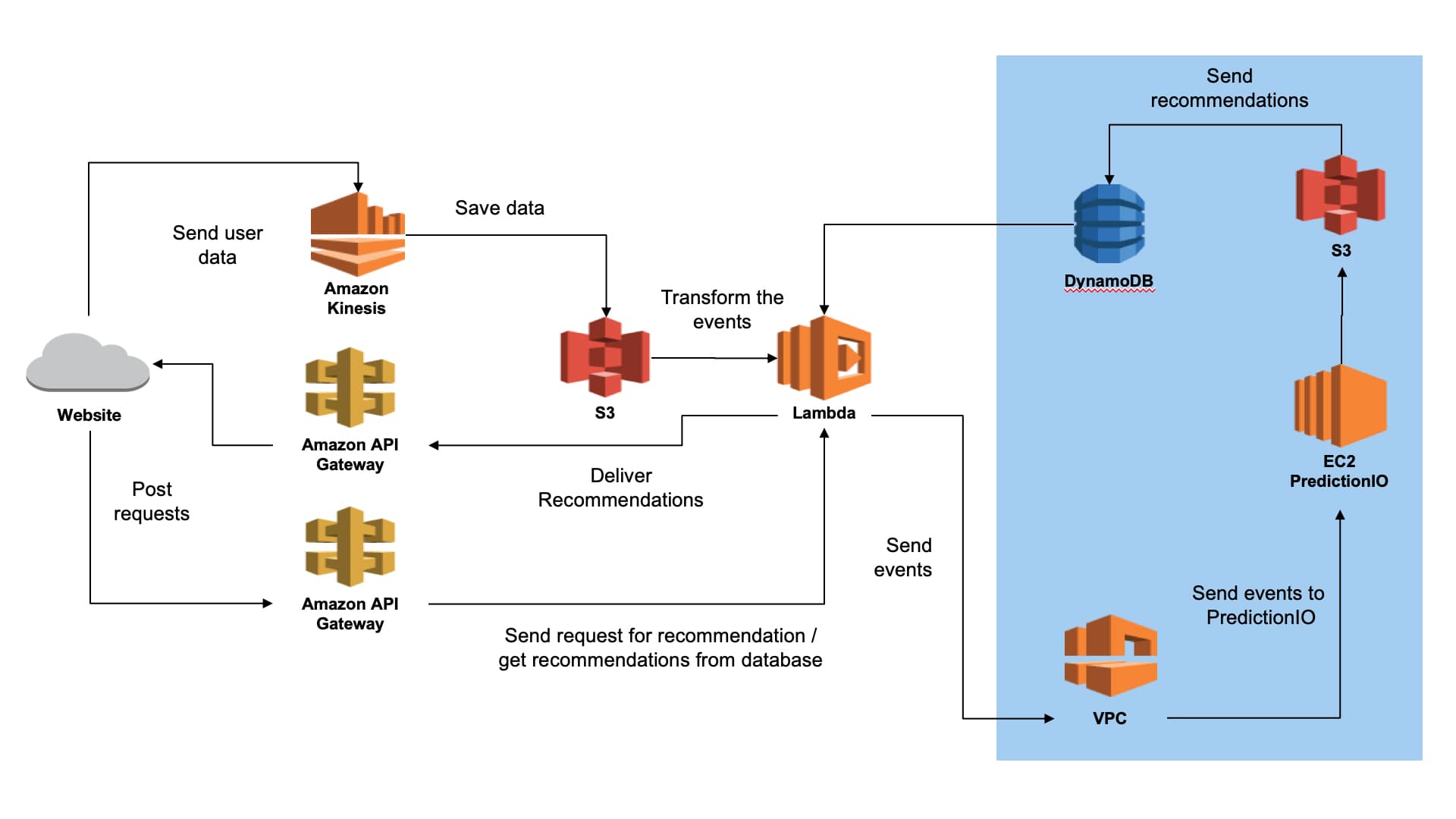
Near-Serverless Architecture
We pieced together our engine and learned a great deal along the way. It didn’t look like this at the beginning. We failed a lot but we learned a great deal more!
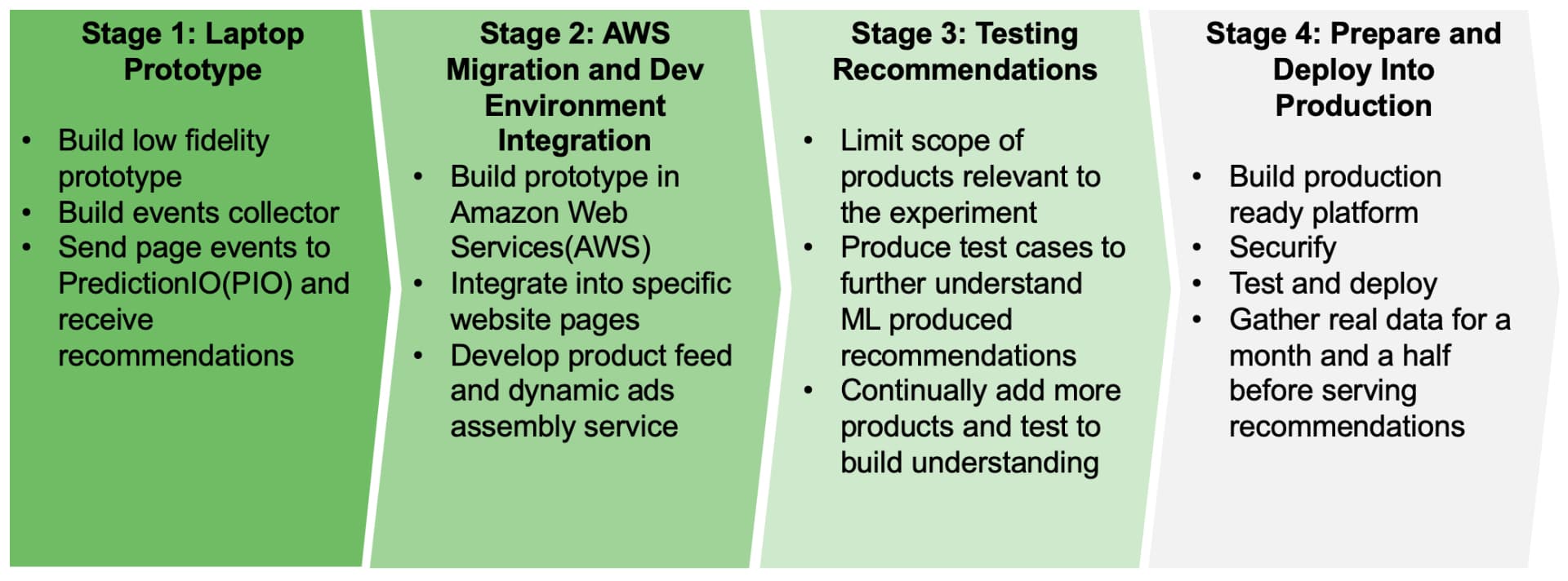
Prototype Roadmap
I was able to minimize my risk by bootstrapping the project and developing with low cost solutions that had very little to no barrier-to-entry. At every stage of prototyping, we began to understand the “ins and outs” of implementing a machine learning platform, testing recommendations in lower environments before production, and building on AWS (which is a joy).
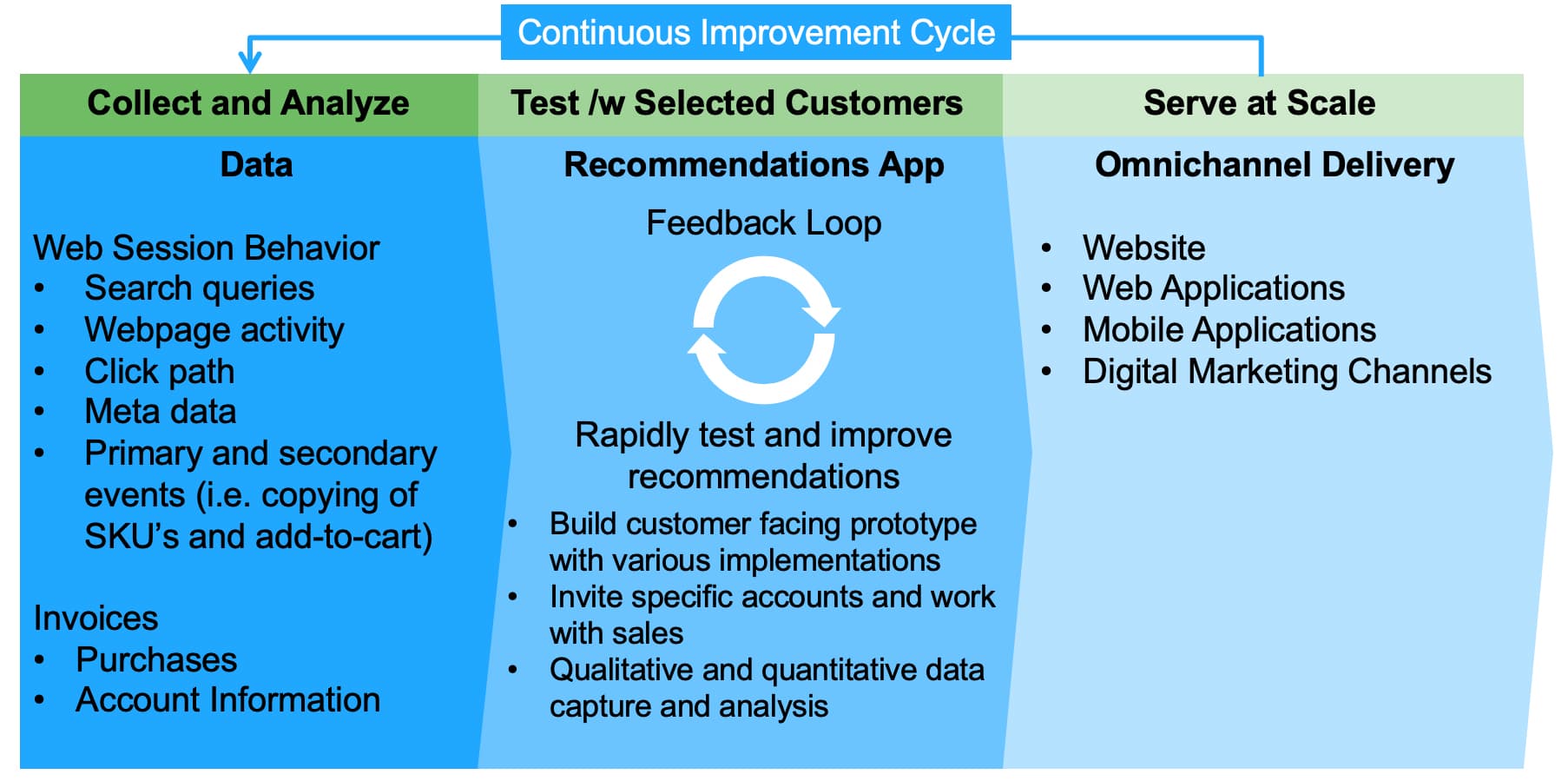
Algorithm Development
I treated algorithm development just like product management.
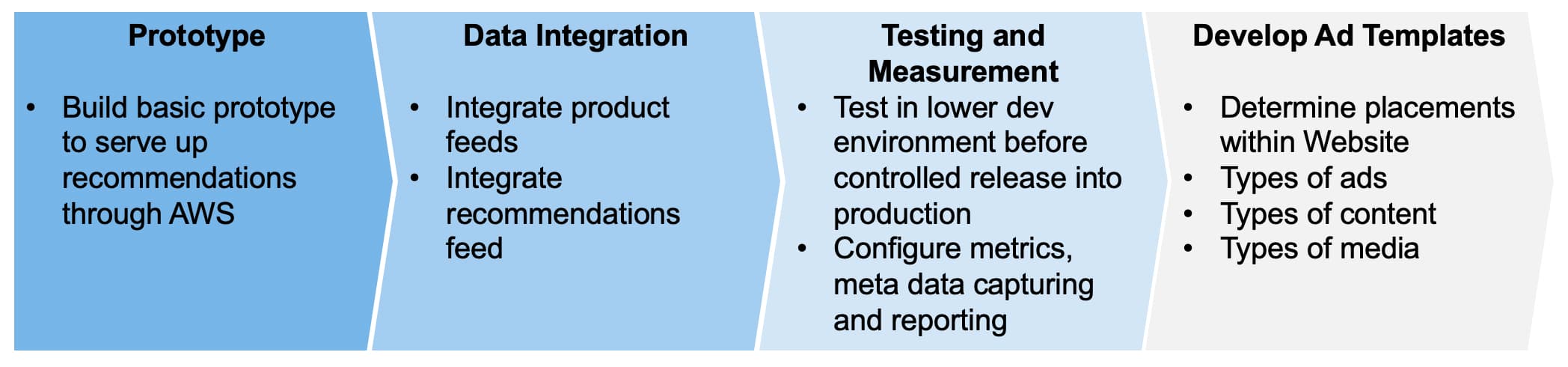
Preparing for Ad Delivery
and Ad Templates
Because our onsite digital ads were being manually produced at the time, this became a bottleneck for a recommendation engine. But this could be solved by combing 1) recommendations data stream paired with SKU and userID 2) a database containing SKU, product page URL, image URL 3) a backend process to assemble these recommendations in a cache or assembled in real-time during first paint.
Project Impact
Our first implementation of machine learning and developing in cloud in a small prototype context helped the company understand the complexities in a large global enterprise setting. We started small and kept iterating until we achieved an operational near real-time automated product recommendation engine. I would definitely would like to do this again but with 100% serverless architecture!
Although the project came to an end, it spawned even more eCommerce machine learning projects, dedicated funding, and continued support from leadership.
"Accelerating discovery, enhancing life."